前言¶
在实现限速功能的时候,其中一种常用的方法是使用 token bucket 算法来实现。
token bucket¶
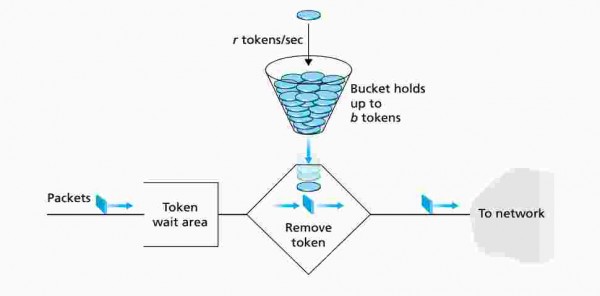
(图片来自 https://gateoverflow.in/39720/gate2016-1-54 )
token bucket 常见的中文解释是:令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务 [1] 。
维基百科 [2] 上 token bucket 算法的简单描述如下:
- A token is added to the bucket every 1/r seconds. 每隔 1/r 秒向 bucket 中增加一个 token。
- The bucket can hold at the most b tokens. If a token arrives when the bucket is full, it is discarded. 这个 bucket 最多只能存放 b 个 token。如果放置 token 时 bucket 已经满了,丢弃这个 token。
- When a packet (network layer PDU) of n bytes arrives,
当一个包含 n 个字节的数据包进来的时候,
- if at least n tokens are in the bucket, n tokens are removed from the bucket, and the packet is sent to the network. 如果 bucket 中有 >= n 个 token,将从 bucket 中移除 n 个 token,然后把这个数据包发送出去。
- if fewer than n tokens are available, no tokens are removed from the bucket, and the packet is considered to be non-conformant. 如果可用的 token < n,此时不会从 bucket 中移除任何的 token,但是这个数据包会被认为是被限制的数据包。
常见实现方法¶
一般有两种实现方法。
一种是按照 token bucket 的说明,真的做放 token 的操作:
- 后台有个线程每 1/n 秒将 bucket 中的 token 数量加一,直至达到 bucket 容量。
- 主线程检查限速时,比较 bucket 中 token 的数量,如果少于需要的数量,表示当前被限制。 (比如,一个请求进来,检查 bucket 中的 token 数量是否 > 1,如果 > 1请求放行同时把 token 数量减 1, 如果 < 1 说明当前请求已超出速率限制,请求被拒绝。)
这种方法有一个很大的缺点,那就是因为每个 token bucket 都会有一个繁忙的后台线程在更新 token 数量,会 导致严重占用系统 CPU 出现严重的性能问题。假设我们的限速是限制为 1000/s,此时后台每隔 1ms 就会更新一次 token 数量,可以想像每个后台线程都会频繁占用 CPU,用这种方法实现的 rate limiting 处理不了几个请求就会出现 CPU 接近 100% 的情况。所以实践中一般用另一种方法来实现 token bucket。
另一种是在取 token 时计算上次取跟这次取之间按照速率会产生多少个 token 加上上次剩余的 token (不能超过 bucket 容量限制),然后比较剩余 token 数是否满足需要。
特点¶
通过 token bucket 的介绍以及对具体实现的了解,可以发现 token bucket 有以下特点:
- 当 bucket 满的时候,将不再放入 token,即 token 数不能超过 bucket 容量限制。
- 因为可以一次性从 bucket 拿出大量的 token 所以 token bucket 允许突发的峰值, 即,限速不是绝对的,而是允许存在尖峰/波峰。
总结¶
本文简单介绍了一下 token bucket 算法以及两种常见的实现方法。
{kind=link}
Comments