前提:
windows + pelican 3.1 + python 2.6
并且 pelican 配置文件中设置了 USE_FOLDER_AS_CATEGORY = True(默认为 True,只要不设置为 False 即可)
默认情况下,pelican 不支持中文文件夹作为分类目录:
d:\myblog>pelican content -o output -s pelicanconf.py -D
...
CRITICAL: 'utf8' codec can't decode byte 0xd3 in position 2: invalid continuation byte
Traceback (most recent call last):
File "C:\Python26\Scripts\pelican-script.py", line 9, in <module>
load_entry_point('pelican==3.1', 'console_scripts', 'pelican')()
File "C:\Python26\lib\site-packages\pelican\__init__.py", line 319, in main
pelican.run()
File "C:\Python26\lib\site-packages\pelican\__init__.py", line 152, in run
p.generate_context()
File "C:\Python26\lib\site-packages\pelican\generators.py", line 337, in generate_context
.decode('utf-8')
File "C:\Python26\lib\encodings\utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeDecodeError: 'utf8' codec can't decode byte 0xd3 in position 2: invalid continuation byte
从错误信息中我们可以看到 pelican 对文件夹名称默认按 utf8 编码进行解码,而在 windows 下文件(夹)名称默认是按 gbk 进行编码的,所以就出现了编码错误。
下面我们来修复这个错误。
编辑文件 C:\Python26\lib\site-packages\pelican\generators.py 进行以下两步操作即可:
- 首先导入 sys 模块:
import sys - 然后编辑第 338 行左右的
category = os.path.basename(os.path.dirname(f))\ .decode('utf-8')
为
category = os.path.basename(os.path.dirname(f))\ .decode(sys.stdin.encoding)
此处的修改是为了让程序使用系统默认的输入编码(简体中文版 Windows 下默认是 gbk)进行解码。
进行相关修改后,再次执行 pelican content -o output -s pelicanconf.py -D 生成 html 文件,执行过程一切顺利。
但也有一个不完美的地方:
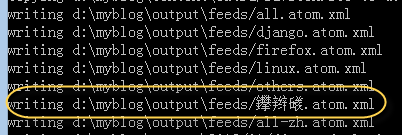
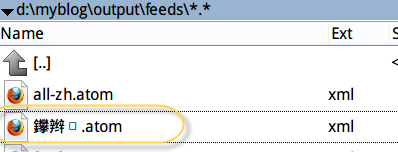
虽然在浏览器中这个不会是乱码,但看起来还是有点不爽。 下面我们要将它变成中文拼音,这样就不会乱码了。
继续编辑 generators.py 文件:
- 导入相关模块:
from pelican.utils import slugify。 这个模块的作用是将非 ASCII 字符转换为 ASCII 字符,比如,将中国转换为zhong-guo。 - 将 199 行左右的
for cat, arts in self.categories: arts.sort(key=attrgetter('date'), reverse=True)
改为
for cat, arts in self.categories: cat = slugify(cat) arts.sort(key=attrgetter('date'), reverse=True)
修改后的效果:
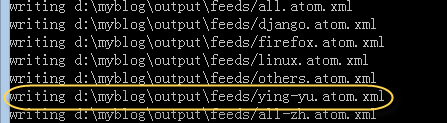
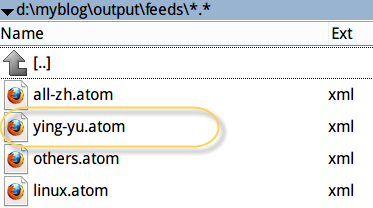
{kind=link}
Comments